事故定级的时候我们应该考虑什么?
最近遇到一起比较典型的事故,稍微带有一些特殊点,然后上下游开始争论起来了事故定级应该谁承担什么责任,谁是责任方,谁是主责的问题。
比较典型,所以简单写写自己的思考。
大概的情况是这样的,
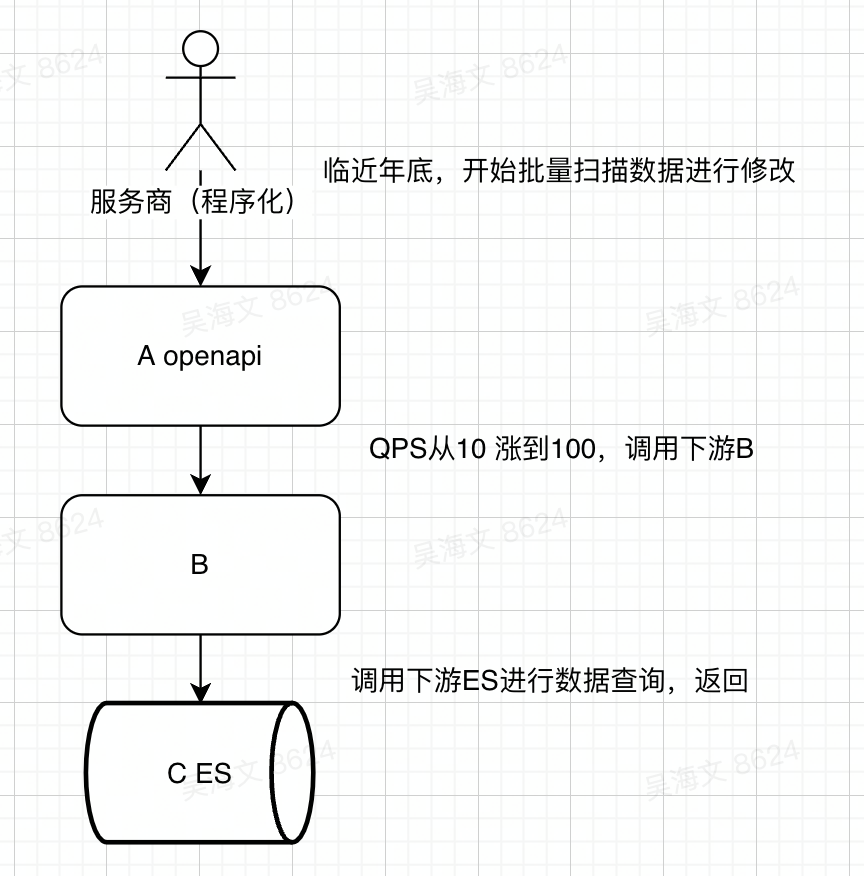
其中AB都是X业务的服务,夸业务调用C的接口,实际非核心依赖,挂掉无所谓的,但是因为历史原因,没有做好降级和强弱依赖梳理,导致C的接口挂了后,进而引发了一连串的核心功能出问题。事故级别比较高;
简单描述就是A是一个对外的OPENAPI服务,被客户用接口调用来修改数据,临近年底客户需要批量修改数据,正好是个特殊场景,平时打到最底下的E的接口的QPS是5个每秒左右,比较低,但年底这个特殊场景,事故时从5逐步上升到100左右,进而打卦了下游的ES存储引擎。
在事故定级时,A认为C是主责,原因为:
1. C没做限流,导致ES被打挂;
2. C在100QPS不算高的时候被打卦了,不应该;
而C认为不应该是C的责任,原因如下:
1. 跨业务调用但是不应该是核心依赖,并且C都不知道A调用的场景和作用是什么,之前也没有过沟通对齐;
2. A代码中不合理的核心依赖没有及时梳理管理,导致低优先级的接口影响主体功能;
3. 年底了A的客户有重要行为变化,进而引起C的接口上涨从5->100,涨幅过大没有通知下游;
然后两个团队在这个事情上展开了多轮次的PK和讨论,并升级了多次来沟通。
最终结果是A没再继续讨论了。
下面讲讲我的理解和我们在事故定级中应该考虑什么,原则是什么
我们鼓励什么样的行为
下面分析case中几个要先确定的问题。来看事故定责我们倡导什么,容忍什么。
如果我们鼓励下游要抗住接口的多倍的压力
那团队以后就会出现大家分配很多倍的资源buffer来应对这种大概率可能不会出现的情况,进而浪费公司服务器,存储,计算等资源。比如每个服务为了避免接口涨一倍而挂掉,要承担责任,那能做的就是提前准备2倍的服务器,这显然从公司角度是无法承受的。
一般最佳实践是根据平时公司的产品特性来确定一个常规的上涨幅度,比如30%,那大家都需要至少让自己的服务有30%的buffer来应对可能的尖峰,这是必须的。但要准备1倍,2倍,甚至更多倍,是不行的。
总结:这种时候我们需要确定一个常规合理的buffer空间,上游在这个buffer空间内的涨幅,下游必须能抗住。否则是下游的服务运维不合理的事情了。
再大,就是上游的问题,或者没限流的事情了。
我们鼓励上游还是下游来主动发起限流?
显然,这个答案也比较简单,不过可能当事人会迷。
我们有应该鼓励的是下游主动发起,不过可能初期只能是服务开始的时候做好限流,很难做到频繁的对齐。
原因:限流主要是for下游视角避免下游被打卦,那O在下游这边,所以她需要主动去找上游沟通。当日可能对于老业务,需要有个过程。
不过这里缺一不可,限流也需要得到上游的沟通确认,比如如果限流出问题,你的依赖是核心依赖,下游随机限流,那必然还是会影响用户的请求,灾难还是发生了。
所以限流必须两方一起确认,同时沟通强弱依赖。
强依赖应该哪方发起确认?
上面的例子,A把C作为强依赖了, C 不知道,A 的老代码一直没清理。
那这个事情应该谁来发起沟通确认呢?
答案是上游。因为如果是下游,就会出现一个结果:下游频繁不断的可能双月,要找下游对齐SLA,以及你是否把我作为强依赖了。这个沟通效率是很低的,并且O不是下游而是上游的,所以为了保证自己服务稳定性,强弱依赖应该是上游来负责梳理并且找下游对齐SLA。
谁的收益谁主动的原则。
规则的制定者应该考虑机制运行后,团队会怎么考虑,怎么运行
上面的几个问题例子,其实背后更重要的是需要我们不断的思考,我们确定一个规则后, 生态会怎么样,团队会怎么反应,效率会变成什么样的?
这些问题是规则制定时要重点考虑的,没考虑长远就只会定时爽,定完下面执行的时候开始变味。
有些时候挺佩服国家的一些鼓励,刺激政策,以及经济政策的,国家不是经济的执行者,而是规则的制定者,需要考虑这个规则制定后,生态会怎么发展,挺有意思的。

近期评论