geth以太坊源码分析-P2P模块基于UDP的服务发现机制原理(1)
以太坊的底层P2P模块承担了节点之间的通信和服务发现,新节点发现连接的功能,对于geth来说,P2P模块氛围2个部分:
- 节点发现, 怎么发现附近的其他节点;
- 节点连接,怎么去连接其他节点并互相通信;
以太坊使用UDP进行服务发现,通讯内容比较简单,所以没有加密。而使用TCP进行真正的数据传输和交互,这部分是使用加密连接进行传输的。
本文先来分析一下以太坊是怎么来发现周边其他节点的,后面在讲如何使用。
之前文章中讲过,以太坊会动P2P服务, P2P服务的discover会自动发现附近的节点,具体是在p2p/server.go 里面进行启动的。
数据结构
服务发现功能由p2p/discover 包来管理,主要是2个重要的结构,udp 和Table 结构。先来了解一下P2P服务发现的几个重要数据结构:
udp 协议处理模块
udp 结构用来记录对应的监听UDP链接,以及最重要的是匿名组合了Table结构,这结构主要用来处理协议交互通讯,握手的功能。
type udp struct {
//真正的UDP连接
conn conn
netrestrict *netutil.Netlist
priv *ecdsa.PrivateKey
ourEndpoint rpcEndpoint //UDP 对应的TCP地址,端口一样
//用来接受pending()函数上面设置的各个等待事件,然后会立即放到其他地方
addpending chan *pending
//用来处理收到数据后的处理流程的
gotreply chan reply
closing chan struct{}
nat nat.Interface
//匿名组合功能,这样udp也拥有了Table的方法
*Table
}
Table 地址管理模块
Table 类用来管理所有的邻近节点,以及进行邻近节点的重连等处理,如果涉及到要链接进行握手的,则会调用udp的函数进行处理, Table类也会保留一个net指针,其实是udp类。这样能够调用商城的接口进行协议握手交互处理。
type Table struct {
mutex sync.Mutex // protects buckets, bucket content, nursery, rand
//所有节点都加到这个里面,按照距离
buckets [nBuckets]*bucket // index of known nodes by distance
//是bootstrap 启动节点
nursery []*Node // bootstrap nodes
rand *mrand.Rand // source of randomness, periodically reseeded
ips netutil.DistinctNetSet
db *nodeDB // database of known nodes
refreshReq chan chan struct{}
initDone chan struct{}
closeReq chan struct{}
closed chan struct{}
bondmu sync.Mutex
bonding map[NodeID]*bondproc
bondslots chan struct{} // limits total number of active bonding processes
nodeAddedHook func(*Node) // for testing
//net上有实现应用层的握手协议等ping, waitping,findnode, 交互还是得调用上层
net transport
self *Node // metadata of the local node
}
服务初始化过程
在P2P服务的Start过程中,会先建立UDP监听端口,注意服务的发现是使用UDP协议的,这样跟TCP协议通信有这本质区别,不需要进行连接建立三次握手等过程。直接发送UDP数据报文出去就可以了。
if !srv.NoDiscovery || srv.DiscoveryV5 {
//网络发现服务, 用UDP协议 , 这里的目的是生成一个udp协议地址字段, 设置一个UDP listen监听句柄
addr, err := net.ResolveUDPAddr("udp", srv.ListenAddr)
if err != nil {
return err
}
//下面这个会将这个udp连接设置为listen状态
conn, err = net.ListenUDP("udp", addr)
if err != nil {
return err
}
realaddr = conn.LocalAddr().(*net.UDPAddr)
}
只要没有关闭discovery服务发现功能,P2P服务就会调用discover.ListenUDP(conn, cfg) 去开启服务发现功能。开启后台协程进行UDP监听, 如果有新的数据包到来,会通知到 unhandled(如果用的是DiscoveryV5) 上面, discover包会使用conn这个UDP 监听链接,不断读取数据包进行处理, 同时,discover会自己维护cfg上面设置的Bootnodes 初始连接节点,进而进行p2p扩展,不断发送findnode包询问最近的临接节点,并加入到自己的Table ntab 是discover.udp结构,同时也匿名继承了discover.Table类。
if !srv.NoDiscovery {
cfg := discover.Config{
PrivateKey: srv.PrivateKey,
AnnounceAddr: realaddr,
NodeDBPath: srv.NodeDatabase,
NetRestrict: srv.NetRestrict,
Bootnodes: srv.BootstrapNodes, //初始启动peer节点
Unhandled: unhandled,
}
//开启后台协程进行UDP监听, 如果有新的数据包到来,会通知到 unhandled(如果用的是DiscoveryV5) 上面
//discover包会使用conn这个UDP 监听链接,不断读取数据包进行处理
//同时,discover会自己维护cfg上面设置的Bootnodes 初始连接节点,
//进而进行p2p扩展,不断发送findnode包询问最近的临接节点,并加入到自己的Table.buckets列表中
//ntab 是discover.udp结构,同时也匿名继承了discover.Table类
ntab, err := discover.ListenUDP(conn, cfg)
if err != nil {
return err
}
srv.ntab = ntab
}
服务发现主要就是discover 包处理的事情,起创建函数为ListenUDP, 实际上调用newUDP()进行处理。
开启UDP监听
newUDP 是一个比较重要的函数,负责开启后台协程进行UDP监听, 如果有新的数据包到来,会通知到 unhandled(如果用的是DiscoveryV5) 上面给P2P服务使用。同时还会调用newTable来创建一个节点管理器。
func newUDP(c conn, cfg Config) (*Table, *udp, error) {
udp := &udp{
conn: c,
priv: cfg.PrivateKey,
netrestrict: cfg.NetRestrict,
closing: make(chan struct{}),
gotreply: make(chan reply),
addpending: make(chan *pending),
}
realaddr := c.LocalAddr().(*net.UDPAddr)
if cfg.AnnounceAddr != nil {
realaddr = cfg.AnnounceAddr
}
// TODO: separate TCP port
//拆分出一个ip端口的rpcEndpoint,其实就是UDP -》 转成对应的TCP地址
udp.ourEndpoint = makeEndpoint(realaddr, uint16(realaddr.Port))
//下面传入udp结构创建一个table结构,table负责对P2P协议节点发现功能的逻辑
//但是对于怎么对接点进行握手,交互收据,得依靠应用层udp提供ping,waitping, findnode 接口,
//这样table对于节点的应用层处理逻辑,调用上层的接口即可
tab, err := newTable(udp, PubkeyID(&cfg.PrivateKey.PublicKey), realaddr, cfg.NodeDBPath, cfg.Bootnodes)
if err != nil {
return nil, nil, err
}
//显示的设置这个匿名组合的Table, 这个跟简单的匿名组合不一样,需要显示指定table指针
udp.Table = tab
具体看上面的注释,newTable 返回一个Table类然后设置到udp.Table匿名继承成员上。
进行上面的初始化后会调用udp.loop进行握手协议层的处理,这个后面讲。并且会调用udp.readLoop进行UDP包读取,解析。
//发送数据
go udp.loop()
//读取数据,并调用 handlePacket进行处理
go udp.readLoop(cfg.Unhandled)
return udp.Table, udp, nil
}
newTable函数调用的时候,会传递Bootnodes变量,这就是UDP服务的初始连接节点了,服务器启动默认从这些节点开始进行节点发现,进行扩散。
func newTable(t transport, ourID NodeID, ourAddr *net.UDPAddr, nodeDBPath string, bootnodes []*Node) (*Table, error) {
// If no node database was given, use an in-memory one
db, err := newNodeDB(nodeDBPath, Version, ourID)
tab := &Table{
net: t, //net上有实现应用层的握手协议等ping, waitping,findnode, 交互还是得调用上层
//----
}
if err := tab.setFallbackNodes(bootnodes); err != nil {
return nil, err
}
for i := range tab.buckets {
tab.buckets[i] = &bucket{
ips: netutil.DistinctNetSet{Subnet: bucketSubnet, Limit: bucketIPLimit},
}
}
tab.seedRand() //设置随机种子
//加载所有的种子节点,其中包括参数bootnodes 里面的节点, 暂时不需要进行连接,连接在后面的loop之前进行
tab.loadSeedNodes(false)
tab.db.ensureExpirer()
go tab.loop()
return tab, nil
握手协议
先来讲一下UDP服务发现的握手协议,便于后面理解p2p服务是怎么进行服务发现的。
一共涉及到几个交互的数据包:
1. ping 测试对端节点是否正常,如果正常会发回一个pong包;
2. pong 节点应答包,表示我活着,可用;
3. findnode 邻近节点查询请求,用来查找距离某个节点比较近的其他节点;
4. neighbors 是findnode的回包,里面包含了邻近节点的列表;
所以基本的流程就如下:
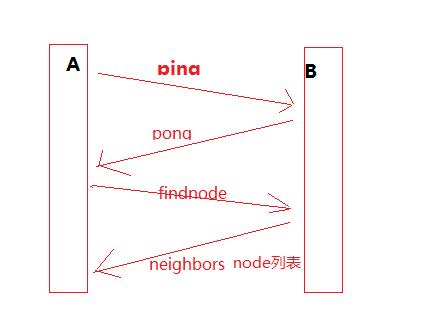
测试邻近节点连通性
由于是UDP协议,所以没有连接的概念,需要不断的去ping来测试对端节点是否OK。,上面看到在newTable后面,创建了一个协程go tab.loop(),来看看p2p服务是怎么根据bootsnode来扩展发现其他节点的。
func (tab *Table) loop() {
var (
revalidate = time.NewTimer(tab.nextRevalidateTime())
refresh = time.NewTicker(refreshInterval) //30分钟进行刷新所有节点列表进行findnode
copyNodes = time.NewTicker(copyNodesInterval)
revalidateDone = make(chan struct{})
//监听doRefresh 是否完成
refreshDone = make(chan struct{}) // where doRefresh reports completion
waiting = []chan struct{}{tab.initDone} // holds waiting callers while doRefresh runs
)
// Start initial refresh.
//先进行刷新,这也是启动p2p服务的第一次尝试连接其他节点
go tab.doRefresh(refreshDone)
可以看到loop协程会立即再创建一个doRefresh协程来尝试连接其他节点,这也是第一次去做节点刷新和连接。传入的参数refreshDone管道用来主协程和刷新协程进行通信。
下面进入doRefresh来看一下代码。
func (tab *Table) doRefresh(done chan struct{}) {
//本函数在协程loop里面调用个,去连接我附近的所有节点,
//第一步先连接我链接的所有节点,然后再去lookup其他节点如果链接成功就加入到节点列表。
defer close(done)
// Load nodes from the database and insert
// them. This should yield a few previously seen nodes that are
// (hopefully) still alive.
//真正触发连接节点,newTable的时候不会,doRefresh在协程loop里面调用,比较安全
tab.loadSeedNodes(true)
// Run self lookup to discover new neighbor nodes.
//根据最近的节点进行findNode查找邻近节点, 进行一次扩展, 查找其他节点的peers
//首先找距离我自己最近的节点
tab.lookup(tab.self.ID, false)
上面主要2部分,loadSeedNodes触发连接节点,lookup进行节点发现,也是服务发现的2个最主要的部分。
loadSeedNodes()触发连接节点
loadSeedNodes 功能是 加载所有种子节点,包括tab.nursery 上设置的 Bootnodes初始启动节点, loadSeedNodes在上面见过了2次,一次是newTable, 另外一次是在Table的loop协程里面。
如果是newTable初始化阶段,不会开始连接,bond为false, 到后面的go协程里面进行loop的时候,会先调用tab.doRefresh 来触发tab.loadSeedNodes(true);
func (tab *Table) loadSeedNodes(bond bool) {
//加载所有种子节点,包括tab.nursery 上设置的 Bootnodes初始启动节点
//如果是newTable初始化阶段,不会开始连接,bond为false
//到后面的go协程里面进行loop的时候,会先调用tab.doRefresh 来触发tab.loadSeedNodes(true)
seeds := tab.db.querySeeds(seedCount, seedMaxAge)
seeds = append(seeds, tab.nursery...)
if bond {//刚开始创建table的时候,参数bond是false, 不会触发连接的
seeds = tab.bondall(seeds)
}
for i := range seeds {
seed := seeds[i]
age := log.Lazy{Fn: func() interface{} { return time.Since(tab.db.bondTime(seed.ID)) }}
log.Debug("Found seed node in database", "id", seed.ID, "addr", seed.addr(), "age", age)
//一个个将其加入到tab.buckets列表,之前未连接的节点会放到Replacement里面
tab.add(seed)
}
}
可以看到主要是bondall函数,传入查到的种子节点。bondall函数比较简单,直接对每一个节点,开一个协程处理,调用bond函数:
func (tab *Table) bondall(nodes []*Node) (result []*Node) {
//开个协程来一个连接对应的节点,然后等待结果,返回所有性连接的节点列表
rc := make(chan *Node, len(nodes))
for i := range nodes {
go func(n *Node) {
nn, _ := tab.bond(false, n.ID, n.addr(), n.TCP)
rc <- nn
}(nodes[i])
}
for range nodes {
if n := <-rc; n != nil {
result = append(result, n)
}
}
return result
}
发送ping连接节点
bond尝试连接一个节点,发送ping并等待pond,如果能联通,加入table。
func (tab *Table) bond(pinged bool, id NodeID, addr *net.UDPAddr, tcpPort uint16) (*Node, error) {
//尝试连接一个节点,发送ping并等待pond,如果能联通,加入table.
node, fails := tab.db.node(id), tab.db.findFails(id)
//如果是第一次进来,那么这个age会很大,就能进去
age := time.Since(tab.db.bondTime(id))
var result error
if fails > 0 || age > nodeDBNodeExpiration {
log.Trace("Starting bonding ping/pong", "id", id, "known", node != nil, "failcount", fails, "age", age)
tab.bondmu.Lock()
w := tab.bonding[id]
if w != nil {
// Wait for an existing bonding process to complete.
tab.bondmu.Unlock()
<-w.done
} else {
// Register a new bonding process.
//增加一个管道,用来等待完成
w = &bondproc{done: make(chan struct{})}
tab.bonding[id] = w
tab.bondmu.Unlock()
// Do the ping/pong. The result goes into w.
//下面尝试给对方发送ping并且阻塞得到结果后,返回,此时会审查一个w.n = NewNode 记录这个节点
tab.pingpong(w, pinged, id, addr, tcpPort)
// Unregister the process after it's done.
tab.bondmu.Lock()
delete(tab.bonding, id)
tab.bondmu.Unlock()
}
// Retrieve the bonding results
//err上对应结果
result = w.err
if result == nil {
//w.n上就是对应的这个节点的信息了,pingpong函数设置的
node = w.n
}
}
// Add the node to the table even if the bonding ping/pong
// fails. It will be relaced quickly if it continues to be
// unresponsive.
if node != nil {
//node不为空,链接成功,会将节点加入到table里面
tab.add(node)
tab.db.updateFindFails(id, 0)
}
return node, result
}
bond函数比较长,最重要的就是调用 tab.pingpong(w, pinged, id, addr, tcpPort) 用来进行真正的节点测试。
pingpong给对方发送UDP请求, 具体的请求内容由table.net 也就是udp 实现的接口来指定,具体在p2p/discover/udp.go。
func (tab *Table) pingpong(w *bondproc, pinged bool, id NodeID, addr *net.UDPAddr, tcpPort uint16) {
//给对方发送UDP请求, 具体的请求内容由table.net 也就是udp 实现的接口来指定,具体在p2p/discover/udp.go
// Request a bonding slot to limit network usage
//控制一下频率,一个个来
<-tab.bondslots
defer func() { tab.bondslots <- struct{}{} }()
// Ping the remote side and wait for a pong.
//table.ping 含简单,实际上是调用的tab.net.ping。实际上调用的是应用层的udp.ping,后者会组建一个ping包,里面包括版本号,from,to节点,以及过期时间。
//发送后会等待结果,如果成功,ping函数才会返回
//发送一个ping的UDP消息给对方,并且等待pong结果返回,如果失败会返回非空,成功返回nil
//debug.PrintStack()
if w.err = tab.ping(id, addr); w.err != nil {
close(w.done)
return
}
//如果之前没有ping过, 现在成功了,那就等一下对方会不会来ping我们。
//如果不会,这里会超时的
if !pinged {
// Give the remote node a chance to ping us before we start
// sending findnode requests. If they still remember us,
// waitping will simply time out.
tab.net.waitping(id)
}
//超时之后,增加这个节点
// Bonding succeeded, update the node database.
w.n = NewNode(id, addr.IP, uint16(addr.Port), tcpPort)
close(w.done)
}
上面有意思的点是bondslots 用来做频率控制,go语言的管道真是,挺好用的,让代码简洁度高不少。
tab.ping(id, addr) 调用了tab.net.ping(), 代码如下, 用来发送一个ping的UDP消息给对方,并且等待pong结果返回,如果失败会返回非空,成功返回nil。
func (t *udp) ping(toid NodeID, toaddr *net.UDPAddr) error {
//发送一个ping的UDP消息给对方,并且等待pong结果返回,如果失败会返回非空,成功返回nil
req := &ping{
Version: Version,
From: t.ourEndpoint,
To: makeEndpoint(toaddr, 0), // TODO: maybe use known TCP port from DB
Expiration: uint64(time.Now().Add(expiration).Unix()),
}
packet, hash, err := encodePacket(t.priv, pingPacket, req)
if err != nil {
return err
}
//先挂一个回调,这样发送完收到结果的时候,触发errC
//pending 返回的是一个结果通知管道
errc := t.pending(toid, pongPacket, func(p interface{}) bool {
return bytes.Equal(p.(*pong).ReplyTok, hash)
})
t.write(toaddr, req.name(), packet)
//发送后会等待结果,如果成功,ping函数才会返回
//在loop()里面会监听r.gotreply事件,从plist里面找到对应的链家然后在p.errc <- nil
//这样本函数才会返回nil
return <-errc
}
同样,上面的代码精妙之处在于,t.pending函数传入了一个匿名函数,当回调函数。完了直接调用t.write来发送一个UDP数据包给对方。之后等待在errC管道上。这个来做什么的呢?errc 是t.pending返回的管道。来看看代码:
func (t *udp) pending(id NodeID, ptype byte, callback func(interface{}) bool) <-chan error {
//ping或者findnode函数调用这里,设置一个ping返回调用,并等待errC
//生成一个结果通知管道,生成一个pending结构放入t.addpending 里面,对方接到请求会调用callback,然后触发errC
ch := make(chan error, 1)
p := &pending{from: id, ptype: ptype, callback: callback, errc: ch}
select {
case t.addpending <- p:
// loop will handle it
case <-t.closing:
ch <- errClosed
}
//返回这个ch给调用者去等待,而对于addpending的对端,
//也就是loop,这会在获取到一个ptype类型后,会发送一个nil给这个errC的管道
//这样做到阻塞的目的, 调用者只需要等待在这管道上即可
return ch
}
具体看注释,清洗了,调用write发送UDP报文后,会往 t.addpending 上发送一个pending消息,消息里面设置了一个管道ch,也就是errC,这样在udp的loop函数里面接到addpending消息后,会登记这个关系。
实际上pending顾名思义,就是等级等待事件,如果等待成功,loop协程会调用传入的callback函数,然后往管道errC发送一个结果。
来看一下loop的相关处理:
func (t *udp) loop() {
select {
case p := <-t.addpending:
//ping 会设置一个pending的回调,将待回应的数据发到这个管道,然后才调用write发送数据
p.deadline = time.Now().Add(respTimeout)
//放到plist里面,如果有reply到来,会触发t.gotreply来进行扫描调用p.callback,
plist.PushBack(p)
case r := <-t.gotreply:
//收到对方发送的数据包后,就是在readLoop里面不断读取数据包后,调用对应类型的数据包的handle函数
//后者会给gotreply 发送一个管道消息,带着对应的数据包
var matched bool
for el := plist.Front(); el != nil; el = el.Next() {
p := el.Value.(*pending)
if p.from == r.from && p.ptype == r.ptype {
matched = true
if p.callback(r.data) {
//匹配成功,发送nil到管道,通知ping()函数返回
p.errc <- nil
plist.Remove(el)
}
// Reset the continuous timeout counter (time drift detection)
contTimeouts = 0
}
}
//然后给r.matched发送管道消息
r.matched <- matched
看上面代码,清洗了吧,实际上就是主协程loop的时候,addpending会记录这个等待事件,如果gotreply管道上面有消息了,便会遍历所有等待协程,如果match, 就调用其callback然后触发管道。通知等待协程唤醒。
这样当udp.ping函数返回的时候,就是本节点以及收到对端的pong的时候了。
得到对端节点返回的PONG
上面还有一点没有说清楚,就是怎么就收到pong了?这个没讲呀!
上面在发送ping包进行等待的时候,我们可以看到代码是: t.pending(toid, pongPacket, func(p interface{}) bool , 第二个参数代表我要等待对方发送pongPacket。
接下来这就要看发送给我的数据包是怎么处理的了,来看readLoop 协程,在newUDP 函数里面。
func (t *udp) readLoop(unhandled chan<- ReadPacket) {
//死循环不断读取UDP包然后调用handlePacket 进行处理,数据的发送调用write函数 直接发出
defer t.conn.Close()
if unhandled != nil {
defer close(unhandled)
}
// Discovery packets are defined to be no larger than 1280 bytes.
// Packets larger than this size will be cut at the end and treated
// as invalid because their hash won't match.
buf := make([]byte, 1280)
for {//下面是不是死循环了?退出的时候怎么处理的?有没有监听closeing
//测试了一下,死循环了。。。退出不了的,因为没有监听退出事件
//ReadFromUDP是底层函数,就是一个个的接受包,然后进行处理,处理方法就是调用handlePacket
nbytes, from, err := t.conn.ReadFromUDP(buf)
if netutil.IsTemporaryError(err) {
// Ignore temporary read errors.
log.Debug("Temporary UDP read error", "err", err)
continue
} else if err != nil {
// Shut down the loop for permament errors.
log.Debug("UDP read error", "err", err)
return
}
//调用处理函数处理这个package
if t.handlePacket(from, buf[:nbytes]) != nil && unhandled != nil {
select {
case unhandled <- ReadPacket{buf[:nbytes], from}:
default:
}
}
}
}
readLoop死循环不断读取UDP包然后调用handlePacket 进行处理,数据的发送调用write函数 直接发出。这里有个有意思的点,这个协程是无论如何都无法退出的,只要没出错的话,程序退出的时候也不会,因为其没有监听对应的closing管道等。可以看看“geth以太坊源码分析-P2P服务发现 UDP协议存在死循环没有优雅退出”
当ReadFromUDP接到一个UDP报文后,会调用handlePacket处理函数处理这个package。
func (t *udp) handlePacket(from *net.UDPAddr, buf []byte) error {
//处理一个readLoop 里面读取到的UDP数据包,先解码, 然后调用包对应的handle
packet, fromID, hash, err := decodePacket(buf)
if err != nil {
log.Debug("Bad discv4 packet", "addr", from, "err", err)
return err
}
//调用对应的packet类型的handle函数, 比如: neighbors.handle , findnode.handle
//packet类型为 ping,pong,findnode, neighbors 等结构
err = packet.handle(t, from, fromID, hash)
log.Trace("<< "+packet.name(), "addr", from, "err", err)
return err
}
从上面的注释可以看出,package.handle 这个函数依赖于decodePacket 返回的数据包类型,有 ping,pong,findnode, neighbors, 也就是说,对端发送的这个包格式是什么,就调用对应的格式。
因此想到,如果我们发送给对方ping包,那么对方会发送pong回来。因此对应的处理函数就是pong.handle:
func (req *pong) handle(t *udp, from *net.UDPAddr, fromID NodeID, mac []byte) error {
//收到一个pongPacket包,那么,handleReply就得干活了
if expired(req.Expiration) {
return errExpired
}
//通知loop的t.gotreply 去处理,然后返回结果
if !t.handleReply(fromID, pongPacket, req) {
return errUnsolicitedReply
}
return nil
}
handleReply函数用来通知loop协程去处理一个对方发给我们的包,传入报文个是等。
func (t *udp) handleReply(from NodeID, ptype byte, req packet) bool {
//收到一个ptype类型的包的回调
matched := make(chan bool, 1)
select {
//给t.gotreply发送换个数据包过去,给他去处理,怎么处理呢?
//就是调用当初等待在上面的回调函数,然后给回调函数上面的errC发送管道消息
case t.gotreply <- reply{from, ptype, req, matched}:
// loop will handle it
return <-matched
case <-t.closing:
return false
}
}
由此串通了:
- 我们在bondall里面创建协程bond连接对端节点,发送ping并等待pongPackage包的到来;
- readLoop收到对端发送回来的pongPackage后,调用pong.handle 进而 调用handleReply通知loop协程来处理消息。
- loop协程找到对应等待的协程,进而发送消息到errC管道唤醒等待协程。
至此一个UDP 握手完成, ping, pong两个消息,测试对端连通性,如果OK,就加入到ok的节点列表里面。
最后总结一下这中间有哪些协程:
- udp类的udp.loop()协议处理,重连等功能的携程;
- udp.readLoop UDP报文读取协程;
- tab.loop()的节点刷新,重连,状态检查协程。
- tab.doRefresh节点刷新,连接协程;
- 每个节点会创建tab.bond协程去连接节点;
限于篇幅下面拆个文章继续写p2p模块是怎么进行节点发现的。

近期评论