nsqd 源码分析(2)- Topic实现原理
这回记录一下nsqd的topic是怎么实现的。先以官网一张著名的动图开始, 下面这图介绍了发送一条消息到一个topic上的流程:
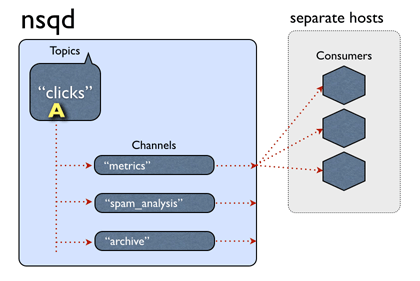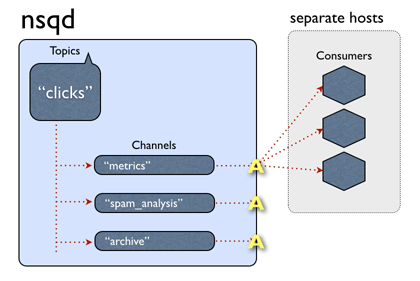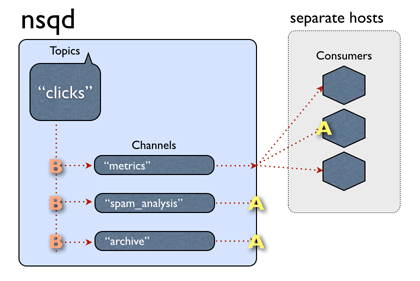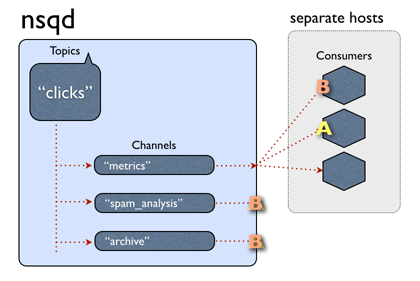
从上图可以看出,nsq的一个topic对应这多个自定义命名的channel, channel后面可以订阅很多个消费者,也就是我们的消费程序了;这中间有个地方要注意,同一个channel后面的消费者,一条消息之后到一个消费者上,但是不同channel的消费者都可以收到,也就是类似于kafka的group一个概念。
具体的不多介绍了,这里只讲实现原理。
一、Topic数据结构
下面是Topic的数据结构(去掉了不重要的变量),所有topic列表会存储在NSQD.topicMap[]里面。
可以看出,最主要的变量在于channelMap,这是这个topic的所有channel结构。memoryMsgChan 是这个topic对应的内存管道, backend是对应的持久化磁盘存储的管道。
type Topic struct {
name string
channelMap map[string]*Channel
backend BackendQueue
memoryMsgChan chan *Message
channelUpdateChan chan int
exitFlag int32 //这个标志是在删除一个topic时,先设置这个,然后在进行真实删除的。PutMessage的时候也会检查这状态,如果正在进行topic删除,那直接返回不入队
ephemeral bool //临时topic以#开头,这样的topic不会写到磁盘上,并且放入内存队列后会丢掉,最后一个channel删除后也会删除这>
个topic,没有持久化
deleteCallback func(*Topic) //topic删除函数,其实是DeleteExistingTopic, 只有在DeleteExistingChannel里面,topic是ephemeral且最后一个channel也删除后会调用
ctx *context
}
上面的ephemeral变量特殊说明一下, 临时topic以#ephemeral开头,这样的topic不会写到磁盘上,并且放入内存队列后会丢掉,最后一个channel删除后也会删除这个topic,没有持久化功能。
下面简单画了一下topic的数据结构流向:

二、如何新建一个topic
新建topic的函数为NewTopic, 新建topic发生的时机在哪些地方呢?
1. loadMetaData加载磁盘文件nsqd.data时,会先创建所有之前的topic;
2. GetTopic 时如果topic不存在,会自动创建一个;
新建topic的步骤为,先new 一个Topic 结构,初始化各项变量;这里如果是临时topic以#ephemeral开头,没有持久化机制,只放入内存中,所以其backend其实是个黑洞,直接丢掉。
如果是正常topic,需要设置其log函数,以及最重要的,backend持久化机制。具体逻辑后面的文章在细化。
初始化变量之后就是最重要的事情了:启动消息协程。最后通知lookupd有新的topic产生。具体如下,可以对应看注释:
func NewTopic(topicName string, ctx *context, deleteCallback func(*Topic)) *Topic {
//初始化一个topic结构,并且设置其backend持久化结构,然后开启消息监听协程messagePump, 通知lookupd
t := &Topic{
name: topicName,
channelMap: make(map[string]*Channel),
memoryMsgChan: make(chan *Message, ctx.nsqd.getOpts().MemQueueSize),
exitChan: make(chan int),
channelUpdateChan: make(chan int),
ctx: ctx,
pauseChan: make(chan bool),
deleteCallback: deleteCallback, //topic删除函数,其实是DeleteExistingTopic
idFactory: NewGUIDFactory(ctx.nsqd.getOpts().ID),
}
if strings.HasSuffix(topicName, "#ephemeral") {
//临时topic以#ephemeral开头,没有持久化机制,只放入内存中,所以其backend其实是个黑洞,直接丢掉
t.ephemeral = true
t.backend = newDummyBackendQueue()
} else {
//正常的topic,需要设置其log函数,以及最重要的,backend持久化机制
dqLogf := func(level diskqueue.LogLevel, f string, args ...interface{}) {
opts := ctx.nsqd.getOpts()
lg.Logf(opts.Logger, opts.logLevel, lg.LogLevel(level), f, args...)
}
//下面初始化一下持久化的diskqueue数据结构, 传入路径和文件大小相关的参数,以及sync刷磁盘的配置
t.backend = diskqueue.New(
topicName,
ctx.nsqd.getOpts().DataPath,
ctx.nsqd.getOpts().MaxBytesPerFile,
int32(minValidMsgLength),
int32(ctx.nsqd.getOpts().MaxMsgSize)+minValidMsgLength,
ctx.nsqd.getOpts().SyncEvery,
ctx.nsqd.getOpts().SyncTimeout,
dqLogf,
)
}
//异步开启消息循环,这是最重要的异步,开启了一个新的携程处理
t.waitGroup.Wrap(func() { t.messagePump() })
//通知lookupd有新的topic产生了
t.ctx.nsqd.Notify(t)
return t
}
这里关于启动消息协程后面在细化,先讲一下删除topic的流程。
三、删除topic
topic的删除主要是调用Delete或者Close 函数,前者会通知lookupd删除所有的topic信息,后者主要用在关闭nsqd服务的时候,关闭本程序的topic。
消息的删除函数,大概做的事情为:
- 通知lookupd删除对应的数据;
- 关闭topic.exitChan管道让topic.messagePump退出;
- 循环删除其channelMap列表;
- 将内存未消费的消息持久化;
Delete实际上调研的是exit()函数,看看代码前半部分实现的功能:
func (t *Topic) exit(deleted bool) error {
//消息的删除函数,大概做的事情为:1. 通知lookupd; 2. 关闭topic.exitChan管道让topic.messagePump退出; 3. 循环删除其channelMap
列表; 4. 将内存未消费的消息持久化;
//先判断一下状态看能否继续删除
if !atomic.CompareAndSwapInt32(&t.exitFlag, 0, 1) {
return errors.New("exiting")
}
if deleted {
t.ctx.nsqd.logf(LOG_INFO, "TOPIC(%s): deleting", t.name)
// since we are explicitly deleting a topic (not just at system exit time)
// de-register this from the lookupd
//通知lookupLoop协程进行处理,有增删topic了,需要进行UnRegister 后者 Register topic了
t.ctx.nsqd.Notify(t)
} else {
t.ctx.nsqd.logf(LOG_INFO, "TOPIC(%s): closing", t.name)
}
//关闭管道,这样其他在这个topic上的协程就会退出, 比如topic.messagePump 就会退出topic消息循环
close(t.exitChan)
//下面其实是在等待启动消息循环的代码退出: t.waitGroup.Wrap(func() { t.messagePump() }), 这样不会再有在这个topic上的操作了
// synchronize the close of messagePump()
t.waitGroup.Wait()
最后一步t.waitGroup.Wait() 其实是在等待topic的消息协程退出,因为上面调用了close(t.exitChan), 说消息协程会收到这个消息并且退出协程。因此这里Wait等待协程退出后,就开始清理channel等信息了。接下来准备清空对应channel的数据 , 看是否是要删除topic来决定调用delete还是close, 这个处理类似topic的处理:
//接下来准备清空对应channel的数据 , 看是否是要删除topic来决定调用delete还是close, 这个处理类似topic的处理
if deleted {
t.Lock()
for _, channel := range t.channelMap {
delete(t.channelMap, channel.name)
channel.Delete()
}
t.Unlock()
// empty the queue (deletes the backend files, too)
t.Empty()
//然后在通知后面的disqqueue进行清理删除
return t.backend.Delete()
}
// close all the channels
for _, channel := range t.channelMap {
err := channel.Close()
}
// write anything leftover to disk
//如果还有内存消息没处理完需要写入后端的持久化设备
t.flush()
return t.backend.Close()
}
四、如何获取Topic
消息获取函数其实是在nsqd.go里面实现的GetTopic , 则函数会先简单获取一把读锁看topic是否已经存在,如果已经存在直接返回,如果不存在就到后面的创建,初始化流程。
先来看一下如果消息存在的情况,nsqd为了降低锁禁止,先获取读锁看一下,然后如果不信,在获取写锁去尝试newtopic。
func (n *NSQD) GetTopic(topicName string) *Topic {
// most likely, we already have this topic, so try read lock first.
//如上面所说,大部分情况都是存在topic的,这优化值得
n.RLock()
t, ok := n.topicMap[topicName]
n.RUnlock()
if ok {
return t
}
//不存在这topc,得new一个了, 所以直接加锁了整个nsqd结构
n.Lock()
t, ok = n.topicMap[topicName]
if ok { //还有种情况,就在刚才那一瞬间,有其他协程进来了,他new了一个,所以获取锁后还得判断一下是否存在
n.Unlock()
return t
}
如果topic不存在,需要新建一个。主要工作由NewTopic来完成,上面讲过,创建一个topic结构,并且里面初始化好diskqueue, 加入到NSQD的topicmap里面。创建topic的时候,会开启消息协程。
另外这里值得提的一电视,函数里面的锁替换,刚开始因为要修改NSQD的topicMap结构,所以必须对nsqd加锁,创建完n.topicMap[topicName] = t 赋值后,就不需要加大锁了,所以先对刚刚创建的topic加一把写锁在释放NSQD的读锁。
这里会不会产生死锁呢?答案是不会,具体看下面的代码注释。
deleteCallback := func(t *Topic) {
//topic的删除函数
n.DeleteExistingTopic(t.name)
}
//创建一个topic结构,并且里面初始化好diskqueue, 加入到NSQD的topicmap里面
//创建topic的时候,会开启消息协程
t = NewTopic(topicName, &context{n}, deleteCallback)
n.topicMap[topicName] = t
// release our global nsqd lock, and switch to a more granular topic lock while we init our
// channels from lookupd. This blocks concurrent PutMessages to this topic.
//可以理解为先加锁topic,这个时候会加不上吗?
//不会,因为我们在获取topic的时候,会先加nsqd的读锁获取topic,然后再第二步进行PutMessage或者DeleteExistingChannel的时候,会加
RLock或者Lock;
//因此,由于本函数开头已经先加了n.Lock()大锁,所以上面第二步不可能进入,因此下面可以直接加t.Lock而不用担心死锁
//这里相当于已经创建了topic到nsqd的topicMap,接下来的事情不涉及到nsqd,而只是topic内部的事情了,所以换一把小一点的锁
t.Lock()
n.Unlock()
后面的步骤就是加载lookupd里面的channel信息,进行初始化数据结构了。最后释放topic锁, 然后往管道channelUpdateChan里面塞入一个事件,通知topic的后台消息协程去处理channel的变动事件。
//lookupd里面存储所有之前的channel信息,所以这里加载一下,这样消息能不丢
// if using lookupd, make a blocking call to get the topics, and immediately create them.
// this makes sure that any message received is buffered to the right channels
lookupdHTTPAddrs := n.lookupdHTTPAddrs()
if len(lookupdHTTPAddrs) > 0 {
channelNames, err := n.ci.GetLookupdTopicChannels(t.name, lookupdHTTPAddrs)
for _, channelName := range channelNames {
//临时topic不需要预先创建,用到的时候再创建就行
if strings.HasSuffix(channelName, "#ephemeral") {
continue
}
//预先创建一个channel,原因呢?为了让消息能够及时的入队.
//比如,我这个nsq重启了,那么重启的这时刻,需要加载曾经的所有channel,以备每一个channel的消息不丢。不然只能等着对方cr
eate了,不方便
t.getOrCreateChannel(channelName)
}
}
t.Unlock()
select {
case t.channelUpdateChan <- 1:
case <-t.exitChan:
}
return t
}
五、如何往Topic发送消息
消息的发送操作是二进制的PUB或者“/pub?topic=testtopic” 接口,后面其实都是调用的(t *Topic) PutMessage函数去真正发送一条消息到一个topic。
// PutMessage writes a Message to the queue
func (t *Topic) PutMessage(m *Message) error {
t.RLock()
defer t.RUnlock()
//简单看一下是不是我们正在退出状态,如果是就直接返回
if atomic.LoadInt32(&t.exitFlag) == 1 {
return errors.New("exiting")
}
err := t.put(m)
if err != nil {
return err
}
atomic.AddUint64(&t.messageCount, 1)
return nil
}
可以看到真正的发送消息函数是put, 我们知道topic存储目标有2个,一个原生内存管道memoryMsgChan,另外一个是持久化存储backend。怎么判别呢?答案就是先看memoryMsgChan是否已经满了,如果满了就不能继续塞了,那就存到后端持久化存储里面去。
memoryMsgChan的容量由 getOpts().MemQueueSize设置,在上面的 NewTopic 函数里面进行初始化,之后不能修改了。
func (t *Topic) put(m *Message) error {
select {
//将这条消息直接塞入内存管道
case t.memoryMsgChan <- m:
default://如果内存消息管道满了(memoryMsgChan的容量由 getOpts().MemQueueSize设置),那么就放入到后面的持久化存储里面
b := bufferPoolGet()
err := writeMessageToBackend(b, m, t.backend)
bufferPoolPut(b)
t.ctx.nsqd.SetHealth(err)
}
return nil
}
topic数据结构主要的差不多了,实现文件在nsqd/topic.go,很简练,总结一下就是nsq的topic主要记录有哪些channel,以及内存管道memoryMsgChan和持久化存储BackendQueue,每一个topic后面会有一个消息协程负责处理这个topic的事务。
用原生内存channel管道当消息队列,也是挺有创意的,不过仔细想想,也有些他的优缺点,比如这channel里的消息,基本上就没有保障了,如果挂了什么的。当然如果为了性能,可以设置容量少一些,但是还是有弊端的。
关于具体后面topic的消息到memoryMsgChan,以及再到channel最后到client的流程,篇幅有点长,改天再写。

近期评论